
Hierarchical Reasoning Model
An in-depth look at Hierarchical Reasoning Models in AI
AI, Machine Learning, Reasoning Models
LLMs with billions of parameters still fail at tasks that require real reasoning. Not vague intuition. Actual multi-step search, backtracking, and planning.
Meanwhile, a 27M parameter model, trained from scratch on about 1000 examples, solves Sudoku, large mazes, and ARC-style reasoning tasks that frontier LLMs fail at completely.
This is not a scaling story. This is an architecture story.
The model is called the Hierarchical Reasoning Model (HRM), introduced in a recent paper from Sapient Intelligence.
At a high level, the idea is simple: stop flattening all computation into a single forward pass. Introduce hierarchy. Let the model think in stages.
What Problem Is HRM Solving?
Transformers are powerful, but they are structurally shallow.
No matter how wide you make them, or how many layers you stack, a standard Transformer performs a fixed amount of computation per forward pass. That puts hard limits on the kinds of problems it can solve efficiently.
This shows up clearly on tasks like:
- Sudoku that requires backtracking
- Maze navigation that requires long-horizon planning
- ARC tasks that require discovering new abstract rules
LLMs rely on Chain-of-Thought to cope with this. They externalize reasoning into text. That helps sometimes, but it is slow, brittle, and extremely inefficient.
HRM takes a different approach: do the reasoning internally, in latent space, without generating intermediate text.
What Is a Hierarchical Reasoning Model?
An HRM consists of two recurrent modules operating at different timescales:
- a low-level module (L) that performs fast, detailed computation
- a high-level module (H) that updates slowly and handles abstract planning
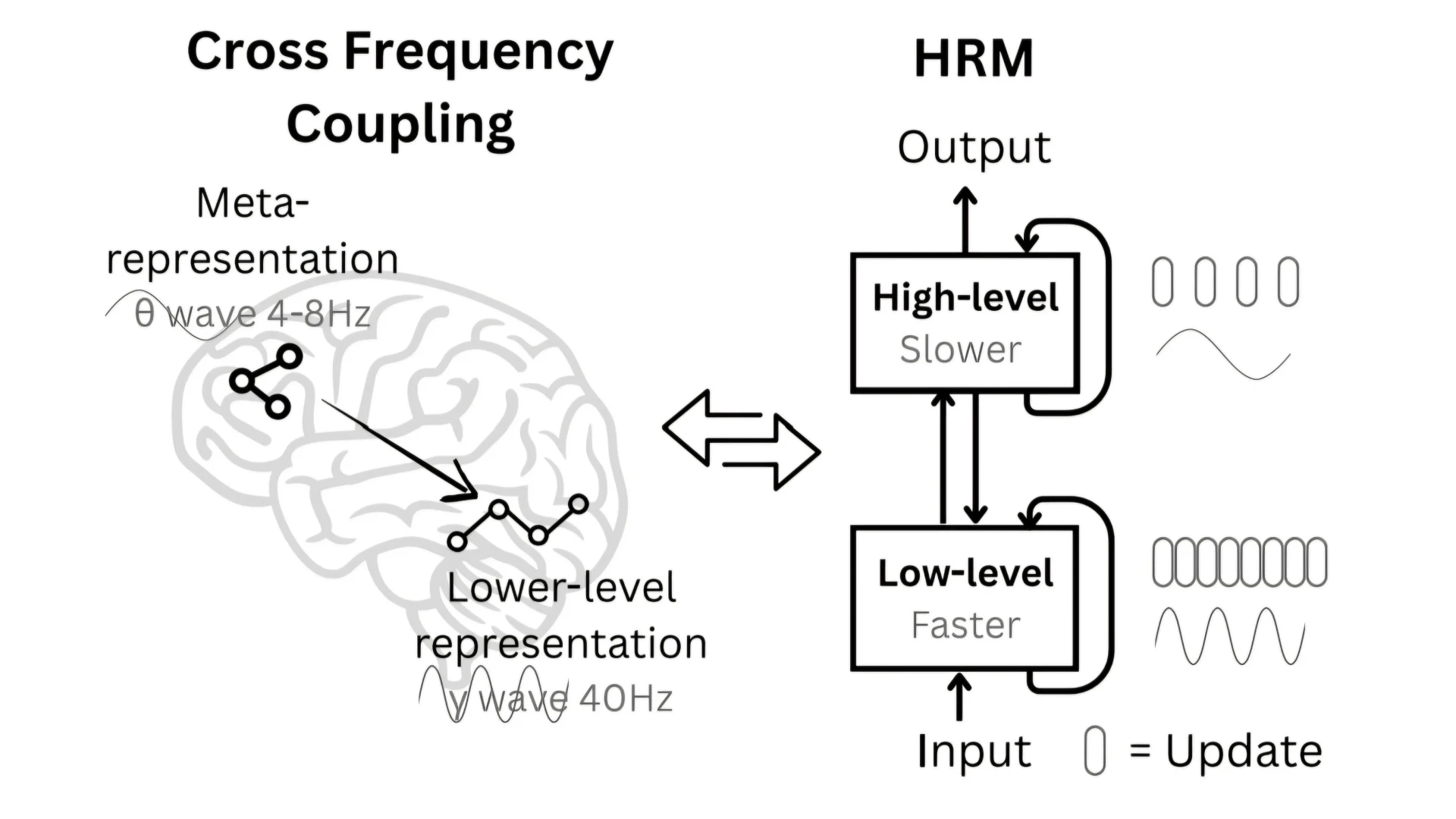
The low-level module is responsible for things like constraint propagation, local search, and refinement. The high-level module observes the outcome of this computation and decides how the process should continue.

The important point is not just hierarchy, but temporal separation.
The low-level module runs for many steps while the high-level module stays fixed. Only after the low-level computation stabilizes does the high-level module update.
How Computation Happens
The model runs in cycles.
In each cycle:
- The high-level state is fixed
- The low-level module iterates until it reaches a local equilibrium
- The high-level module updates once using the final low-level state
- The low-level state is reset
This process repeats multiple times.
Each cycle adds more computation without adding parameters. Effective depth comes from time, not from stacking layers.
This is why HRM can perform hundreds of internal steps in a single forward pass.
Hierarchical Convergence
Standard recurrent networks have a known problem: they converge too quickly. Once the hidden state settles, updates become negligible and computation stalls.
HRM avoids this through what the authors call hierarchical convergence.
The low-level module is allowed to converge, but only temporarily. Each time the high-level module updates, it changes the context and forces the low-level module to start converging again toward a new equilibrium.
This creates a sequence of stable but distinct computation phases.
As a result:
- computation does not die early
- gradients remain useful
- depth scales linearly with the number of cycles
This is the core technical contribution of the model.
Training Without Backpropagation Through Time
Backpropagation Through Time is expensive and does not scale well. Memory usage grows with the number of steps, which makes long-horizon reasoning impractical.
HRM avoids BPTT almost entirely.
Instead, it uses a one-step gradient approximation, inspired by Deep Equilibrium Models. Only the final states of the high-level and low-level modules participate in gradient computation.
All intermediate states are treated as constants.
This reduces memory usage to constant space and makes training stable even with long internal computation.
Deep Supervision
Rather than waiting until the very end to apply a loss, HRM uses deep supervision.
After each full reasoning segment:
- the model produces a prediction
- loss is applied
- the hidden state is detached
- the next segment begins
This gives the high-level module frequent corrective signals and significantly improves training stability.
Adaptive Computation Time
Not every problem needs the same amount of reasoning.
HRM includes an adaptive halting mechanism that decides whether to stop or continue after each segment. The decision is learned using a simple Q-learning setup.
Easy problems terminate early. Hard problems get more compute.
A useful side effect is inference-time scaling. You can increase the maximum allowed computation at inference and get better performance without retraining the model.
What HRM Actually Learns
Visualizing intermediate states shows that HRM learns different strategies depending on the task.
- On mazes, it performs parallel exploration followed by pruning
- On Sudoku, it resembles depth-first search with backtracking
- On ARC tasks, it applies incremental transformations
The same architecture learns different algorithms without any task-specific design.
Emergent Hierarchical Representations
After training, the internal representations of HRM show a clear hierarchy.
- the low-level module operates in a relatively low-dimensional space
- the high-level module expands into a much higher-dimensional space
This hierarchy does not exist in an untrained model. It emerges through learning.
Interestingly, this mirrors observations from neuroscience, where higher cortical areas exhibit richer, higher-dimensional representations than lower sensory regions.
Why More Levels Do Not Help
The authors experimented with adding more hierarchical levels.
Performance generally got worse.
Too many levels increase coordination complexity, weaken gradients, and slow convergence. Two levels appear to be sufficient for most reasoning tasks.
The key is iteration, not deep abstraction stacks.
Why This Matters
HRM challenges several assumptions that dominate current AI research:
- scaling parameters alone improves reasoning
- chain-of-thought is the right way to reason
- Transformers are sufficient for general reasoning
None of these hold up here.
With orders of magnitude fewer parameters and no pretraining, HRM solves problems that state-of-the-art LLMs fail at completely.
This does not mean HRMs are the final answer. But it does strongly suggest that architecture matters, and that reasoning requires models that can perform deep, iterative computation internally.
Scaling token predictors is not enough.
Hierarchy is not a hack. It is a requirement.
What's gonna change?
HRM opens up new directions for building AI systems that can reason without having to rely on scale. But, there is a reason you haven't heard more of it. A new and better achitecture is now under development. TRM.